
The Hairpin Trap in Nutanix Stretched VPCs
How I enabled async routing between datacenters.


When I started working on a stretched VPC across two datacenters, I followed the Nutanix reference guidance almost instinctively. Centralized routing, hairpin traffic to a single site, deterministic behavior. It all made sense on paper.
Then I hit the real environment.
Both datacenters were active. Workloads were distributed. Latency mattered. Forcing traffic to exit from a single site felt artificial and inefficient. That is when I discovered a routing behavior in Flow Networking that is not obvious, not clearly documented, and extremely useful once you understand it.
This article explains what I learned, why the default hairpin model exists, and how I deliberately moved to an async routing design inside a stretched Layer 2 VPC.
The starting point Nutanix hairpin by design
Nutanix guidelines for stretched networking strongly favor a hairpin approach.
- One datacenter acts as the routing and egress hub
- All inter site traffic is forwarded to that site
- Return traffic follows the same path
This model is conservative and intentional. It avoids ambiguity, reduces the risk of asymmetric routing, and makes troubleshooting straightforward.
In many scenarios, it is absolutely the right choice.
The problem I hit in practice
In my case, both datacenters were meant to be peers. There was no real primary site. Workloads were running on both sides, and forcing traffic to hairpin introduced:
- Unnecessary latency for east west flows
- Additional load on inter site links
- An implicit dependency on one datacenter that did not exist at the application level
Layer 2 stretching was already in place, so adjacency was not the issue. Routing intent was.
The key behavior that is easy to miss
Here is the critical detail I discovered.
Even inside a stretched VPC:
- Routing decisions are evaluated locally
- IP classes are treated as local objects
- Flow does not infer remote reachability automatically
Using the same IP class on both clusters does not mean that traffic will be routed between datacenters unless you explicitly tell Flow to do so.
This is the reason why the hairpin model works by default. It removes ambiguity by centralizing intent.
The counterintuitive trick
What surprised me is that Flow already gives you everything you need to go async. You just have to be very explicit.
Even if:
- The VPC is stretched
- The IP classes are identical
- Layer 2 connectivity is working
You still need forward rules on both clusters.
Yes, both. Even though it feels redundant.
The forward rule pattern I used
Instead of a single hairpin rule, I configured symmetric forwarding.
On Cluster A:
- Destination: IP classes hosted in Datacenter B
- Action: Forward
- Next hop: the subnet IP of the stretched VPC on Cluster B, associated with the VPC gateway that establishes connectivity between the two sites
On Cluster B:
- Destination: IP classes hosted in Datacenter A
- Action: Forward
- Next hop: the subnet IP of the stretched VPC on Cluster A, associated with the VPC gateway that establishes connectivity between the two sites
Logically, the destination looks the same. Operationally, Flow evaluates everything in a local context. Without this explicit instruction, traffic never leaves the local routing domain.
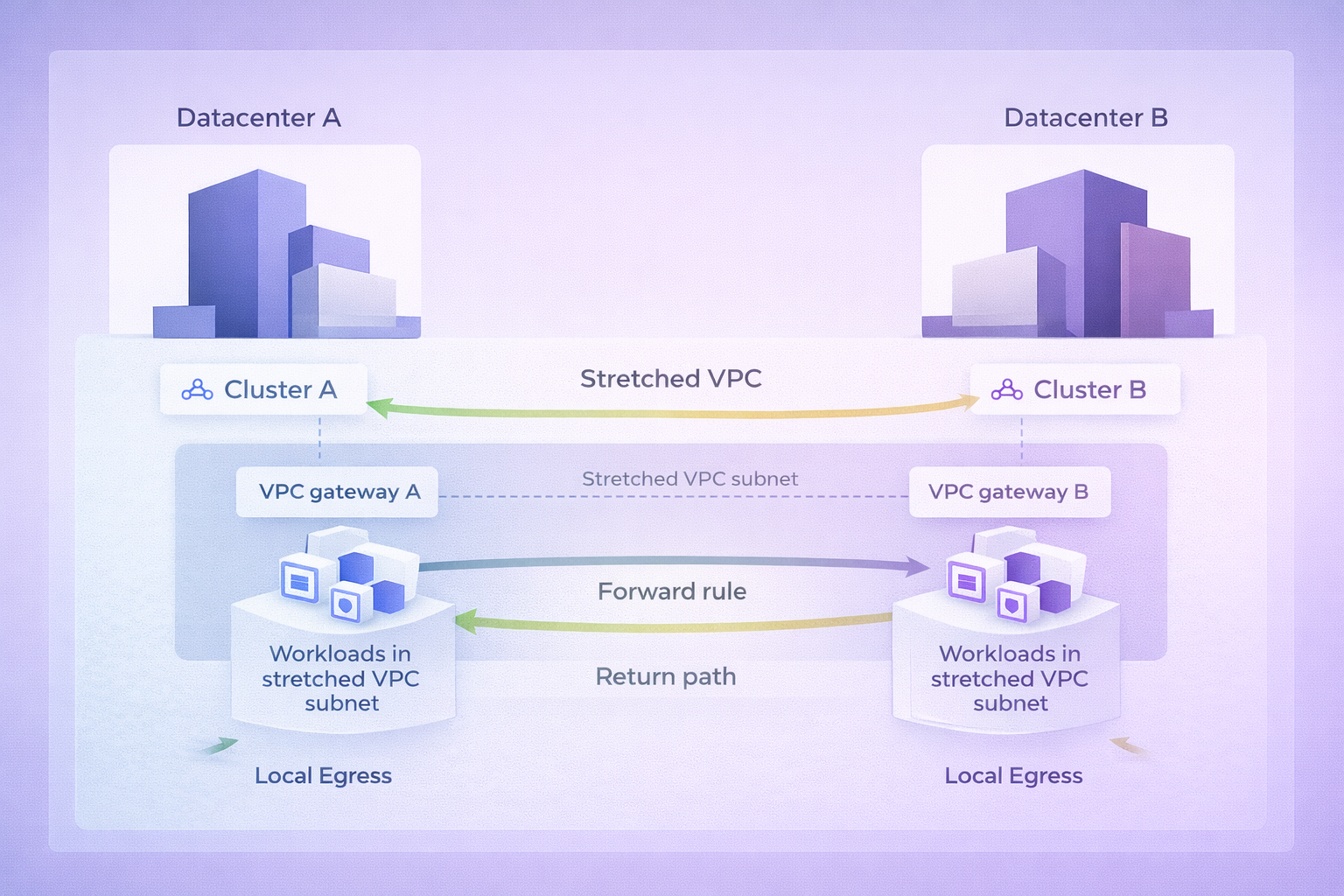
What changes with async routing
Once both rules are in place, behavior changes immediately.
- Each datacenter routes traffic independently
- Egress is local to the workload
- East west traffic follows the shortest path
- There is no implicit primary site anymore
This is true async behavior inside a stretched VPC. No hacks, no unsupported constructs, just a different way of expressing routing intent.
Why this is not the default
After seeing it work, the obvious question is why Nutanix does not recommend this by default.
The answer is discipline.
Async routing requires:
- Perfectly symmetrical policies
- Clear ownership of routing intent
- Strong operational consistency
The hairpin model trades efficiency for predictability. My approach trades simplicity for locality.
Neither is wrong. They solve different problems.
When I would use this again
I would use this pattern when:
- Both datacenters are active by design
- Latency matters
- I want to avoid a hidden primary site
- I fully control the Flow policy model
If you are stretching Layer 2 just for mobility or disaster recovery, hairpin is still the safest choice.
Final thoughts
Stretching Layer 2 gives you adjacency. It does not give you routing for free.
Nutanix guidelines prioritize safety, and for good reasons. Real environments sometimes need different tradeoffs.
This was not a workaround. It was a deliberate architectural decision, made after understanding how Flow actually thinks.
Once you see it, you cannot unsee it.