
Composable Disaster Recovery in Nutanix NCI 7.5
Why async, near-sync, and Metro now coexist as a single design model.


For a long time, I treated disaster recovery as an architectural fork in the road. You picked a model early, async or synchronous, Metro or traditional DR, and then committed the entire platform to that choice. Once decided, everything else had to adapt.
That approach worked, but it came with a cost. It forced rigidity into environments that were anything but static, making disaster recovery feel like a constraint rather than a capability.
Nutanix NCI 7.5 quietly breaks that assumption.
What changes is not a new replication feature or a faster failover workflow. What changes is the way disaster recovery fits into the platform. DR is no longer a mode you enable. It becomes a property you assign, workload by workload, on top of a common, enforced foundation.
Disaster recovery as a platform capability
In previous generations, disaster recovery dictated architecture. Network design, security boundaries, operational workflows, and even organizational processes were often driven by the chosen DR technology.
In NCI 7.5, the relationship is reversed.
The platform provides a consistent set of enforced capabilities. Persistent state ownership at the cluster level. Deterministic networking through VPCs. Security enforcement through Flow Networking. Clear validation rules that prevent ambiguous configurations. Disaster recovery is built by composing these capabilities, not by selecting a single recovery product.
This shift is consistent with a broader change introduced earlier in NCI 7.5, where validated design moves from documentation to enforced platform behavior. I explored this transition in more detail when looking at how Nutanix Infrastructure Manager turns design assumptions into operational guardrails.
By composable disaster recovery, I mean a model where async, near-sync, and Metro are not separate architectures, but different compositions of the same enforced platform capabilities.
Multiple DR modes, one control model
In real environments, not every workload deserves the same level of protection. I have seen platforms where Metro was overused simply because it avoided difficult conversations, and others where async replication was stretched beyond its limits because redesigning the platform felt harder than accepting risk.
Async replication, near-sync replication, and synchronous Metro replication now coexist within the same environment, without forcing parallel architectures.
This control model becomes possible only when networking and security enforcement are no longer centralized workflows, but dedicated control planes operating close to the infrastructure. I previously explored this separation in the context of Flow Networking and its standalone control model.
This matters because it reflects how platforms are actually used. Some workloads need geographic separation and simplicity. Others require near-continuous protection. A small subset demands zero RPO. In NCI 7.5, these are no longer mutually exclusive decisions at the platform level.
The same cluster can host workloads protected by async replication, others by near-sync, and others by Metro. The difference is not in how the platform is built, but in how protection is composed for each workload.
This was not realistically achievable before. Not because features were missing, but because the platform lacked a common enforcement model.
The following diagram captures the common control model that makes multiple disaster recovery modes coexist within the same platform.
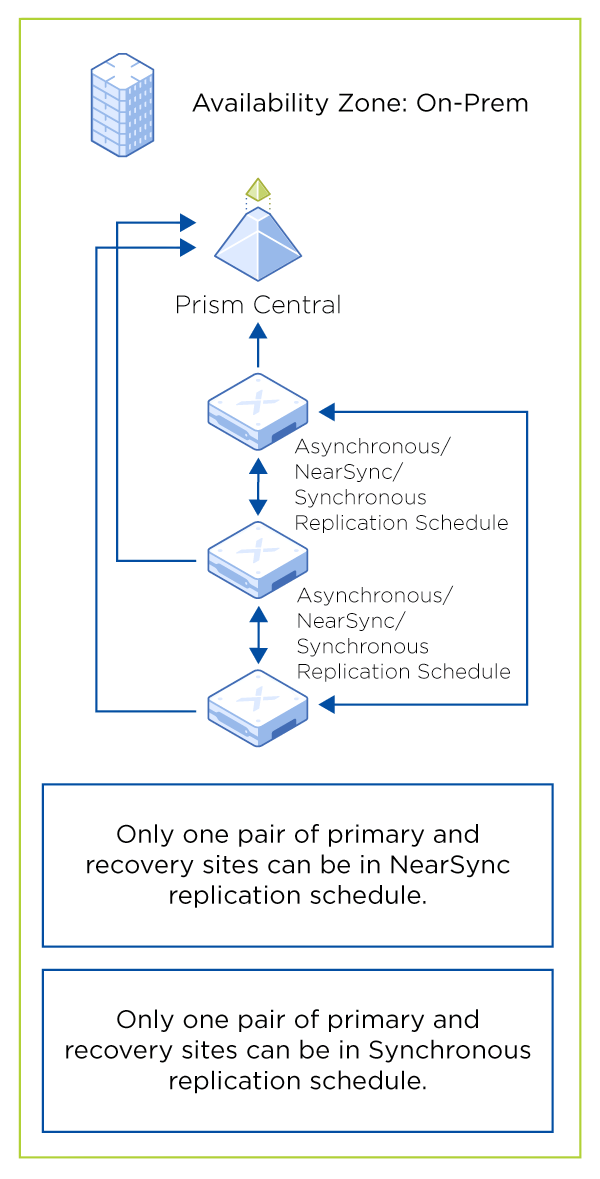
Metro as the upper bound, not the default
Metro remains the most demanding form of disaster recovery. It imposes strict requirements on latency, networking, and operational discipline. What changes in NCI 7.5 is not what Metro is, but where it fits.
Metro is no longer a separate world with its own assumptions. It becomes the upper bound of the same composable model. It relies on the same VPC constructs, the same Flow Networking enforcement, and the same cluster-owned state as async and near-sync replication.
That shift removes the need to treat Metro as a special case, both architecturally and operationally.
Disaster recovery without management plane dependency
One of the most counterintuitive aspects of this model is what happens when the management plane becomes unavailable.
Replication does not stop. Networking does not disappear. Security policies do not relax. Recovery plans do not lose their meaning.
Prism Central governs intent, but it is not responsible for executing disaster recovery at runtime. Replication happens cluster to cluster. Network state lives with the clusters. Security enforcement happens locally. Once protection is defined and validated, it does not require continuous management intervention to remain valid.
The same architectural principle applies to lifecycle operations in constrained environments, where upgrades must succeed without continuous connectivity or external dependencies. I explored this model in more detail when looking at the Dark Site Upgrade Orchestrator in Nutanix NCI 7.5.
This is not an optimization. It is a prerequisite for composability.
The same composable model also applies to how recovery points are handled. Snapshot-based approaches, such as Multicloud Snapshot Technology, align naturally with this design, allowing recovery points to be created and consumed independently on the replication mode, while remaining governed by the same platform-level enforcement.
Validation as enforcement, not friction
Composable disaster recovery only works if the platform refuses ambiguity.
In NCI 7.5, recovery plan validation errors are not advisory. They are hard stops. A recovery does not proceed if prerequisites are not met, if device configurations are incompatible, or if network mappings violate enforced constraints.
This behavior is intentional.
In NCI 7.5, enforcement does not happen when you configure the system.
It happens when the system refuses to enter an invalid state.
That was the point where I realized disaster recovery had stopped being a workflow and had become a property of the platform.
Why this changes how we design platforms
Composable disaster recovery is not about having more options. It is about removing architectural coupling.
When DR becomes a property instead of a mode, platforms can be designed first and protected later. Workloads can evolve without forcing platform redesign. Operational teams can reason about failure scenarios without guessing how the system will behave under stress.
I no longer design platforms around disaster recovery modes. I design platforms that can express multiple recovery behaviors without changing their foundation.
That shift, more than any individual feature, is what makes disaster recovery in Nutanix NCI 7.5 genuinely different.